# 实例化绘制
现在我们的场景还非常简单,其中只有一个 (0,0,0) 为中心的物体。如果想绘制更多物体该怎么办呢?这时可以使用实例化绘制(instancing)。
实例化绘制允许我们以不同的属性(如位置、方向、大小、颜色等)多次绘制同一个对象。有多种方法可以实现实例化绘制,其中一种方法是在 uniform 缓冲区中加入这些属性,并在绘制对象的每个实例前更新它。
但由于性能原因,并不推荐使用这种方法。因为如果对每个实例更新 uniform 缓冲区,需要逐帧创建多份缓冲区的拷贝。除此之外,更新 uniform 缓冲区时还需要创建一个新的缓冲区来存储更新后的数据,这就在 draw call 之间浪费了很多时间。
所幸如果查阅 wgpu 文档 中 draw_indexed 函数的参数,可以找到解决这一问题的方式:
pub fn draw_indexed(
&mut self,
indices: Range<u32>,
base_vertex: i32,
instances: Range<u32> // <-- 在这里
)
参数 instances 是 Range<u32> 类型,它告诉 GPU 应绘制多少份模型的副本(或者说实例)。目前我们指定的是 0...1,表示告诉 GPU 绘制一次模型。如果使用 0...5,代码将绘制 5 个实例。
instances 的 Range<u32> 类型看起来可能有点奇怪,因为如果使用 1...2 的参数,效果也一样是绘制出对象的一个实例。所以似乎直接使用 u32 会更简单?但注意这里使用 range 的原因在于有时我们不想画出所有的对象,而只想画出其中某一部分,因为其他对象可能不出现在这一帧中,或者由于调试而需检查某组特定的实例。
现在我们已经知道如何绘制一个对象的多个实例,那么如何告诉 wgpu 要绘制什么特定的实例呢?这需要用到实例缓冲区这一概念。
# 实例缓冲区
我们将以类似创建 uniform 缓冲区的方式来创建实例缓冲区。首先创建一个名为 Instance 的 struct:
// main.rs
// ...
// NEW!
struct Instance {
position: cgmath::Vector3<f32>,
rotation: cgmath::Quaternion<f32>,
}
Quaternion(四元数)是一种通常用于表示旋转的数学结构。它背后的数学原理有些超纲(涉及虚数和 4D 空间),所以这里不会详细介绍。如果你真的想深入了解这一概念,这里有一篇 Wolfram Alpha 的文章。
在着色器中直接使用这些值会有点麻烦,因为四元数并未在 WGSL 中直接建模。笔者认为在着色器中做相关运算并非最佳实践,所以这里把 Instance 数据转换成矩阵,并将其存储在一个名为 InstanceRaw 的 struct 中:
// NEW!
#[repr(C)]
#[derive(Copy, Clone, bytemuck::Pod, bytemuck::Zeroable)]
struct InstanceRaw {
model: [[f32; 4]; 4],
}
这就是将进入 wgpu::Buffer 的数据。建立这一区分后,即可方便地更新 Instance 而无需操作矩阵,只要在绘制前更新 raw 数据即可。
下面在 Instance 上增加一个方法,实现其到 InstanceRaw 的转换:
// NEW!
impl Instance {
fn to_raw(&self) -> InstanceRaw {
InstanceRaw {
model: (cgmath::Matrix4::from_translation(self.position) * cgmath::Matrix4::from(self.rotation)).into(),
}
}
}
现在我们需要给 State 添加 instances 和 instance_buffer 两个字段:
struct State {
instances: Vec<Instance>,
instance_buffer: wgpu::Buffer,
}
cgmath crate 使用 trait 来提供对其中如 Vector3 等 stuct 常用的数学运算方法,而这些 trait 必须在调用这些方法前导入。为方便起见,crate 内的 prelude 模块在导入时提供了最常用的一些扩展 crate。
要导入 prelude 模块,将这一行放在 main.rs 顶部即可:
use cgmath::prelude::*;
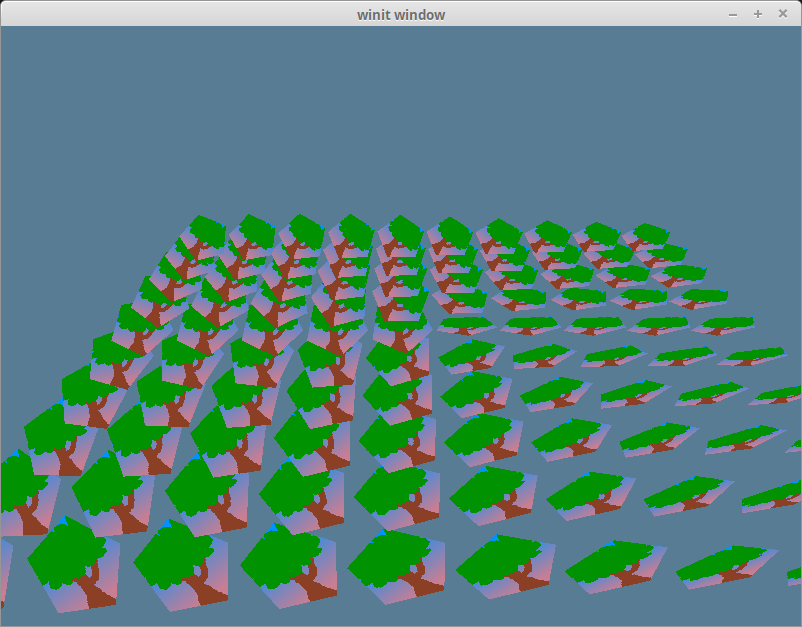
我们将在 new() 中创建实例。为了方便理解,这里会设定一些常数。我们会绘制 10x10 的实例,将它们均匀地隔开:
const NUM_INSTANCES_PER_ROW: u32 = 10;
const INSTANCE_DISPLACEMENT: cgmath::Vector3<f32> = cgmath::Vector3::new(NUM_INSTANCES_PER_ROW as f32 * 0.5, 0.0, NUM_INSTANCES_PER_ROW as f32 * 0.5);
现在可以开始实例化绘制了:
impl State {
async fn new(window: &Window) -> Self {
// ...
let instances = (0..NUM_INSTANCES_PER_ROW).flat_map(|z| {
(0..NUM_INSTANCES_PER_ROW).map(move |x| {
let position = cgmath::Vector3 { x: x as f32, y: 0.0, z: z as f32 } - INSTANCE_DISPLACEMENT;
let rotation = if position.is_zero() {
// 需要这行特殊处理,这样在 (0, 0, 0) 的物体不会被缩放到 0
// 因为错误的四元数会影响到缩放
cgmath::Quaternion::from_axis_angle(cgmath::Vector3::unit_z(), cgmath::Deg(0.0))
} else {
cgmath::Quaternion::from_axis_angle(position.normalize(), cgmath::Deg(45.0))
};
Instance {
position, rotation,
}
})
}).collect::<Vec<_>>();
// ...
}
}
现在我们有了数据,可以创建实际的 instance_buffer 了:
let instance_data = instances.iter().map(Instance::to_raw).collect::<Vec<_>>();
let instance_buffer = device.create_buffer_init(
&wgpu::util::BufferInitDescriptor {
label: Some("Instance Buffer"),
contents: bytemuck::cast_slice(&instance_data),
usage: wgpu::BufferUsages::VERTEX,
}
);
然后需要为 InstanceRaw 创建一个新的 VertexBufferLayout:
impl InstanceRaw {
fn desc<'a>() -> wgpu::VertexBufferLayout<'a> {
use std::mem;
wgpu::VertexBufferLayout {
array_stride: mem::size_of::<InstanceRaw>() as wgpu::BufferAddress,
// 我们需要从把 Vertex 的 step mode 切换为 Instance
// 这样着色器只有在开始处理一次新实例化绘制时,才会接受下一份实例
step_mode: wgpu::VertexStepMode::Instance,
attributes: &[
wgpu::VertexAttribute {
offset: 0,
// 虽然顶点着色器现在只使用位置 0 和 1,但在后面的教程中,我们将对 Vertex 使用位置 2、3 和 4
// 因此我们将从 5 号 slot 开始,以免在后面导致冲突
shader_location: 5,
format: wgpu::VertexFormat::Float32x4,
},
// 一个 mat4 需要占用 4 个顶点 slot,因为严格来说它是 4 个vec4
// 我们需要为每个 vec4 定义一个 slot,并在着色器中重新组装出 mat4
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 4]>() as wgpu::BufferAddress,
shader_location: 6,
format: wgpu::VertexFormat::Float32x4,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 8]>() as wgpu::BufferAddress,
shader_location: 7,
format: wgpu::VertexFormat::Float32x4,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 12]>() as wgpu::BufferAddress,
shader_location: 8,
format: wgpu::VertexFormat::Float32x4,
},
],
}
}
}
我们需要将这个描述符添加到渲染管线中,以便在渲染时使用:
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex: wgpu::VertexState {
// ...
// UPDATED!
buffers: &[Vertex::desc(), InstanceRaw::desc()],
},
// ...
});
也别忘了返回新增的变量:
Self {
// ...
// NEW!
instances,
instance_buffer,
}
最后我们需要改动 render() 方法。这里需要绑定 instance_buffer,并改变在 draw_indexed() 中使用的 range,以传入实例的数量:
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_bind_group(0, &self.diffuse_bind_group, &[]);
render_pass.set_bind_group(1, &self.camera_bind_group, &[]);
render_pass.set_vertex_buffer(0, self.vertex_buffer.slice(..));
// NEW!
render_pass.set_vertex_buffer(1, self.instance_buffer.slice(..));
render_pass.set_index_buffer(self.index_buffer.slice(..), wgpu::IndexFormat::Uint16);
// UPDATED!
render_pass.draw_indexed(0..self.num_indices, 0, 0..self.instances.len() as _);
如果向 Vec 添加新的实例,请确保重新创建 instance_buffer 和 camera_bind_group,否则新实例不会正确显示。
我们需要在 shader.wgsl 中引用新增的矩阵,这样就可以在实例中使用它。在 shader.wgsl 顶部添加以下内容即可:
struct InstanceInput {
[[location(5)]] model_matrix_0: vec4<f32>;
[[location(6)]] model_matrix_1: vec4<f32>;
[[location(7)]] model_matrix_2: vec4<f32>;
[[location(8)]] model_matrix_3: vec4<f32>;
};
在使用矩阵前,我们需要重新组装它:
[[stage(vertex)]]
fn vs_main(
model: VertexInput,
instance: InstanceInput,
) -> VertexOutput {
let model_matrix = mat4x4<f32>(
instance.model_matrix_0,
instance.model_matrix_1,
instance.model_matrix_2,
instance.model_matrix_3,
);
// Continued...
}
我们将在应用 camera_uniform.view_proj 前先应用 model_matrix。这是因为 camera_uniform.view_proj 将坐标系从世界空间变为相机空间。我们的 model_matrix 是一个世界空间中的变换,所以在使用时不希望它处于相机空间:
[[stage(vertex)]]
fn vs_main(
model: VertexInput,
instance: InstanceInput,
) -> VertexOutput {
// ...
var out: VertexOutput;
out.tex_coords = model.tex_coords;
out.clip_position = camera.view_proj * model_matrix * vec4<f32>(model.position, 1.0);
return out;
}
完成后,应该就能看到由一片树构成的森林了!
# 小测验
不妨尝试逐帧修改实例的位置和(或)旋转角。